Prior to the beta launch of the Notion API, our team used to joke that every product announcement resulted in a common refrain:
NOTION: *posts a tweet that does not mention the API*
USERS: "Where is the API?"
There was a huge appetite for an API from users who wanted to extend the power of Notion. Our mission is to make software toolmaking ubiquitous. To effectively do so in today's inter-connected world, Notion has to work with the other tools that users already rely upon.
Many users rightfully asked, "Isn't building a REST API well-trodden territory at this point? What could possibly be so difficult?" These are valid questions, especially in a world with APIs for virtually everything, from fantasy sports data to the New York Times' movie reviews. What makes Notion different?
It turns out that designing a good API for a platform as flexible as Notion poses a surprisingly nuanced challenge! We're sharing some key decisions from our process, in the hopes that our experiences provide insights for other developers while demonstrating what makes the Notion API unique.
Representing page content
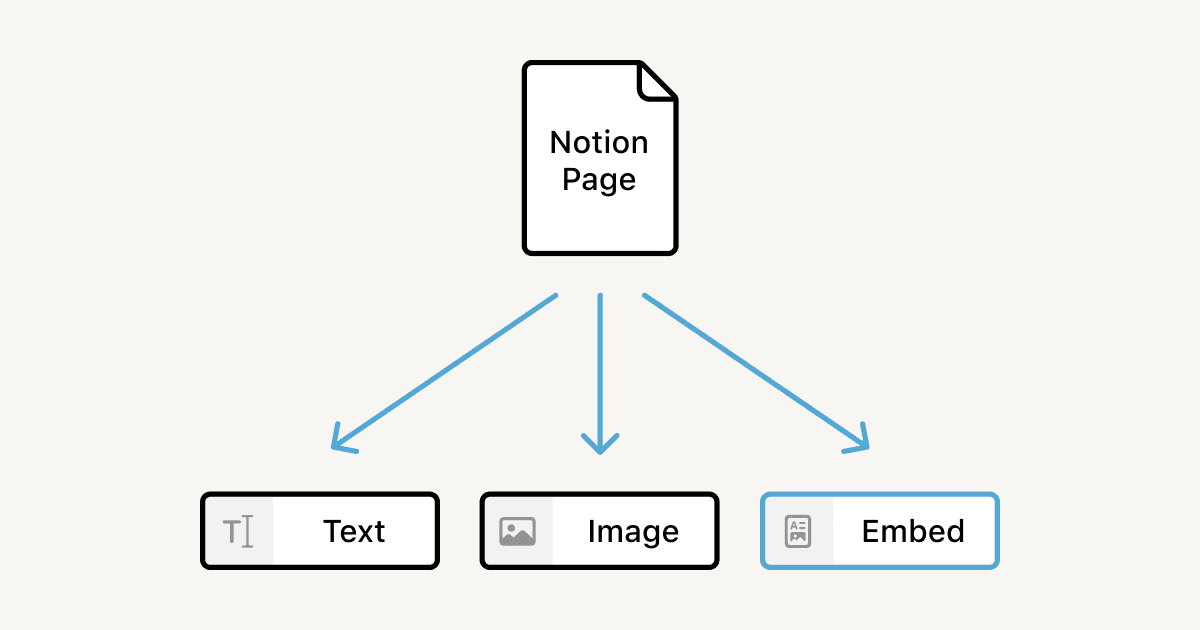
We've previously written about Notion's data model, but to summarize: content is divided into blocks. Everything is a block, from images and bullet list items to database rows and pages themselves.
The heart of our API design problem is figuring out how to translate arbitrary trees of richly-formatted user content into a consistent API that integrates readily with other workflows. Let's break the problem down into two parts: structuring text within blocks, and hierarchical structure across blocks.
Inline rich text formatting
Within each block, Notion supports a rich variety of text formatting operations, ranging from the standard bold and italic to highlights, equations f(x) = x^2 + 1, and more. Not all of these styles are standard, so we needed a portable representation for text, too.
When we decided how to represent page content in the API, there were two main contenders:
Low fidelity, high portability: Markdown, a popular syntax for human-readable plain text formatting. It's a widely-supported format with robust existing tooling, and Notion's editor already supports Markdown shortcuts and exports.
High fidelity, low portability: Custom JSON, based loosely on our internal representation of Notion block values. A tailored schema would capture Notion-specific block types and formatting, at the expense of requiring users to somehow transform this data into their desired output format.
Besides the core fidelity/portability tradeoff, there were several points in favor of Markdown:
Lower implementation and maintenance burden: We wanted to deliver the API as efficiently as possible. Using Markdown, we could leverage Notion's existing Markdown import and export functionality, instead of designing a new data format.
Fewer breaking changes: The silver lining of Markdown's low fidelity is that we can easily change the way we represent blocks, using the limited constructs available. With custom JSON, on the other hand, every new or updated block type would require us to modify the JSON format and possibly release a new API version.
However, the biggest problem with Markdown is that it is simply not expressive enough to support the use-cases that our users wanted an API to fulfill, such as custom importers and exporters to bring data into and out of Notion, or integrations using Notion as a CMS or backing datastore. People have likened Notion to a "blank canvas" and "a place to do messy thinking," because it’s so flexible and expressive. If our API could not replicate what users have spent valuable time creating in Notion, its power and usefulness would be impaired.
Developers are often surprised to learn that the canonical Markdown language reference describes a relatively limited range of formatting constructs.¹ Syntax for tables, inline strikethrough, and fenced code blocks — features closely associated with Markdown today — only emerged as more people began to adapt the language to their needs, triggering a Cambrian explosion of dialects and toolchains (see GitHub-Flavored Markdown, MultiMarkdown, PHP Markdown Extra, R Markdown, CommonMark, and countless ad-hoc implementations).
Documents from one Markdown editor will often parse and render differently in another application. The inconsistency tends to be manageable for simple documents, but it's a big problem for Notion's rich library of blocks and inline formatting options, many of which are simply not supported in any widely-used Markdown implementation. To preserve user content as faithfully as possible, we chose to design a custom JSON representation for rich text.
Paginating block hierarchies
Another strength of custom JSON is that it makes it easier to paginate content trees, a necessity for retrieving large pages. Most blocks support an unlimited number of child blocks, nested arbitrarily deep — imagine a complicated list outline, or the subpage hierarchy of your workspace.
This unbounded structure turns a seemingly simple query, like "fetch the contents of my recipe page," into a more complex problem: how should we batch content blocks in the response?
Breadth-first: Return batches of top-level blocks, without children. Require developers to separately request children to "complete" an individual block. This model makes the most sense from a performance perspective, but it's more of a hassle for clients to retrieve the complete page: they have to make more requests overall, and perform tree insertion to assemble the responses.
Depth-first: Return complete blocks, at the cost of requiring more calls to request top-level blocks further down the page. This model more closely matches most people's intuitions about "return content starting from the beginning and working down the page." However, marshalling a single deeply-nested block could require an unbounded amount of time, which defeats the purpose of paginating in the first place.
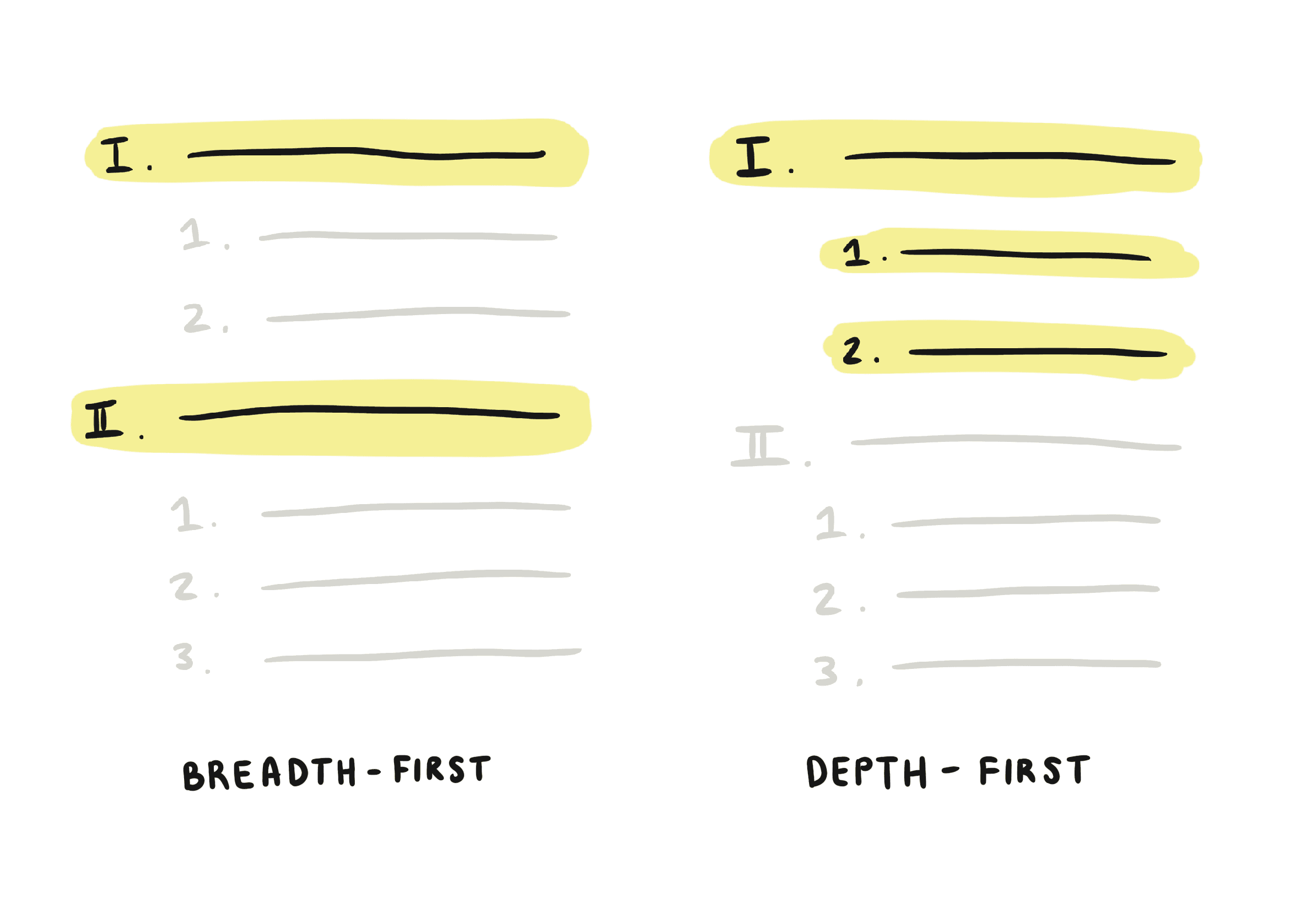
We chose to paginate breadth-first for performance reasons, which directly influenced our document representation. Paginating JSON is pretty straightforward, since blocks retain their UUIDs and other structural metadata. But since Markdown documents don't have much structure (other than newline characters), paginating Markdown is a lot more complicated.
For example, in the breadth-first model we'd have to represent incomplete paragraphs with some kind of marker. These markers need identifiers to help clients insert subparagraphs in the correct position:
Pretty soon, we'd be inventing yet another variant of Markdown and requiring developers to perform tons of string manipulation! It was clear that Markdown's simplicity didn't extend to our complex document model, cementing our decision to use custom JSON to provide developers with greater precision and control.² In the future, our team (or the developer community) can always build conversion tools to translate our custom JSON into standard formats.
Choosing a data format went hand-in-hand with a related question: how to evolve the API over time. There are generally two approaches here:
Per-resource versioning: Each endpoint is versioned and upgraded individually, either by URI (
/v2/users) orContent-Typeheader (Accept: application/notion.v2+json). Resource versioning would enable us to make isolated changes, but major upgrades could require clients to update every URL, not to mention the headaches of dependencies across endpoints (if/v2/pagesrequires/v3/databases, or similar).
Global versioning: Any breaking change creates a new global API version. When enforced, requests must include a header specifying the desired version of the API, or they are assumed to be using the version available at the time their token was granted.
We opted for global versioning, using the Stripe- and AWS-style approach of tagging versions with the date of release instead of having major versions in the URI (api-v2.notion.com). We felt that date-tagged releases would encourage an ethos of small, safe version bumps with correspondingly inexpensive upgrades, rather than the major breaking changes implied by going from v2 to v3.
Fetching page properties
So far, we've mostly talked about documents built from text. But Notion isn't just for notes and to-do lists — we also support custom databases. Pages in a database can have properties based on the database schema. So we needed a way for users to request page properties, and this ended up being surprisingly tricky!
Most properties are straightforward values, such as the person assigned to a project, or a list of tags. When a user requests these simple page properties, we can simply return a JSON representation of the underlying data for each one:

We also support more advanced page properties, such as relations and rollups. These properties make Notion especially powerful for relational data modeling.
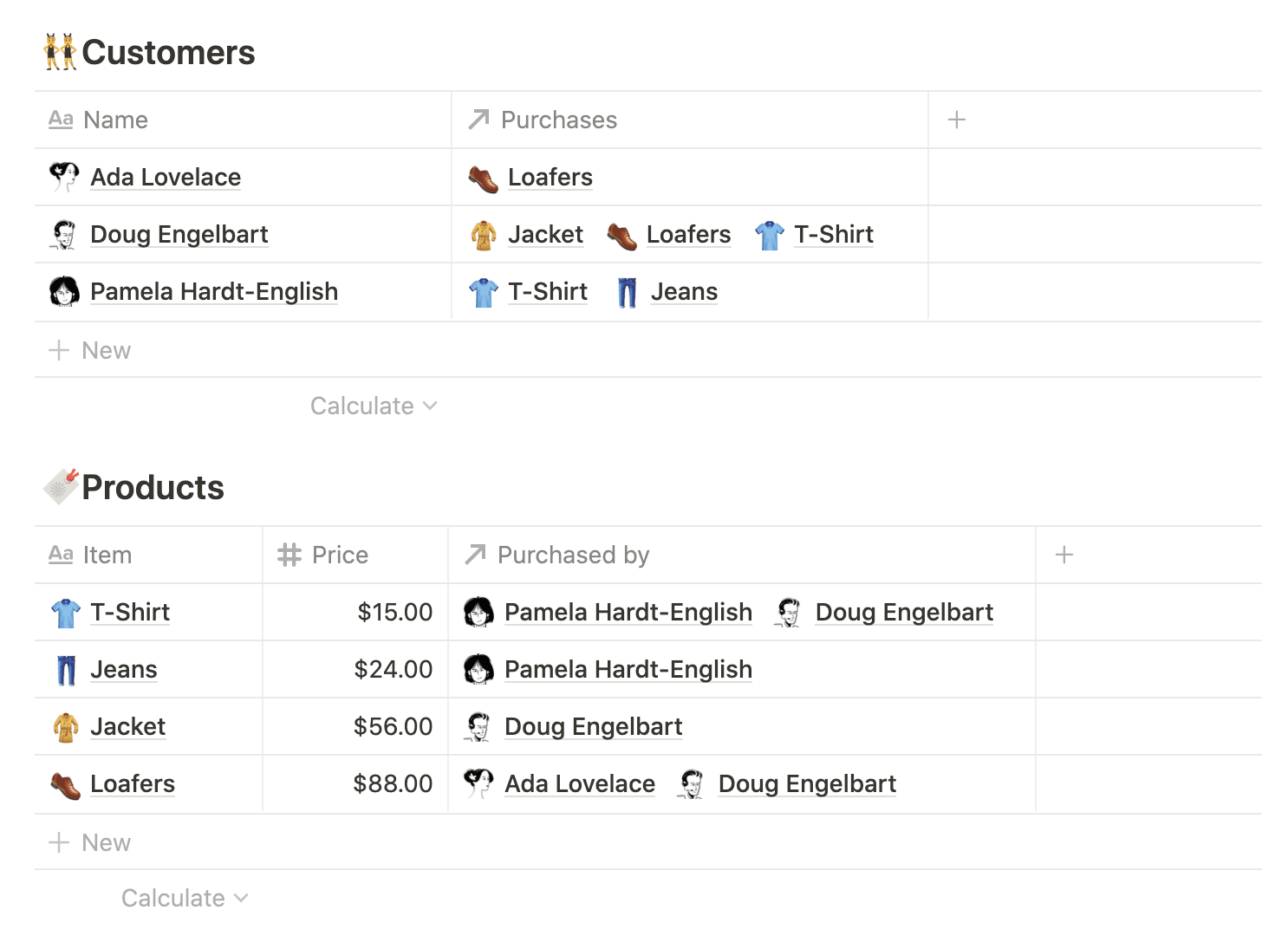
Relations allow users to associate pages across different databases.
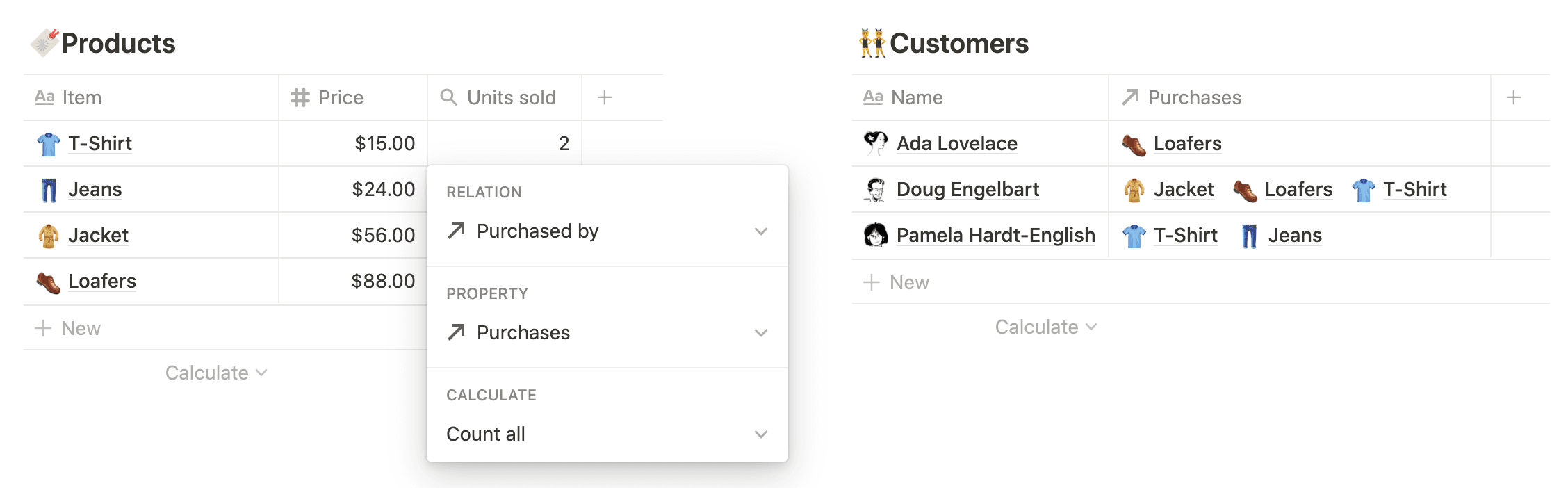
For example, suppose you're a small business owner operating a clothing line. You might have a 🔖 Products database with a price for each item and other details of manufacture, and a 👥 Customers database of recurring buyers. Creating a relation between these databases lets you keep track of who purchased what, in both directions.
Rollups are used to aggregate properties from associated pages.
A rollup has three components: a related database, a property from that database, and an operation to perform over that property. For instance, to determine your top customers you might configure a rollup property in 👥 Customers to show how much each customer has spent:
Related database: 🔖 Products
Property: Price (number)
Operation:
Sum
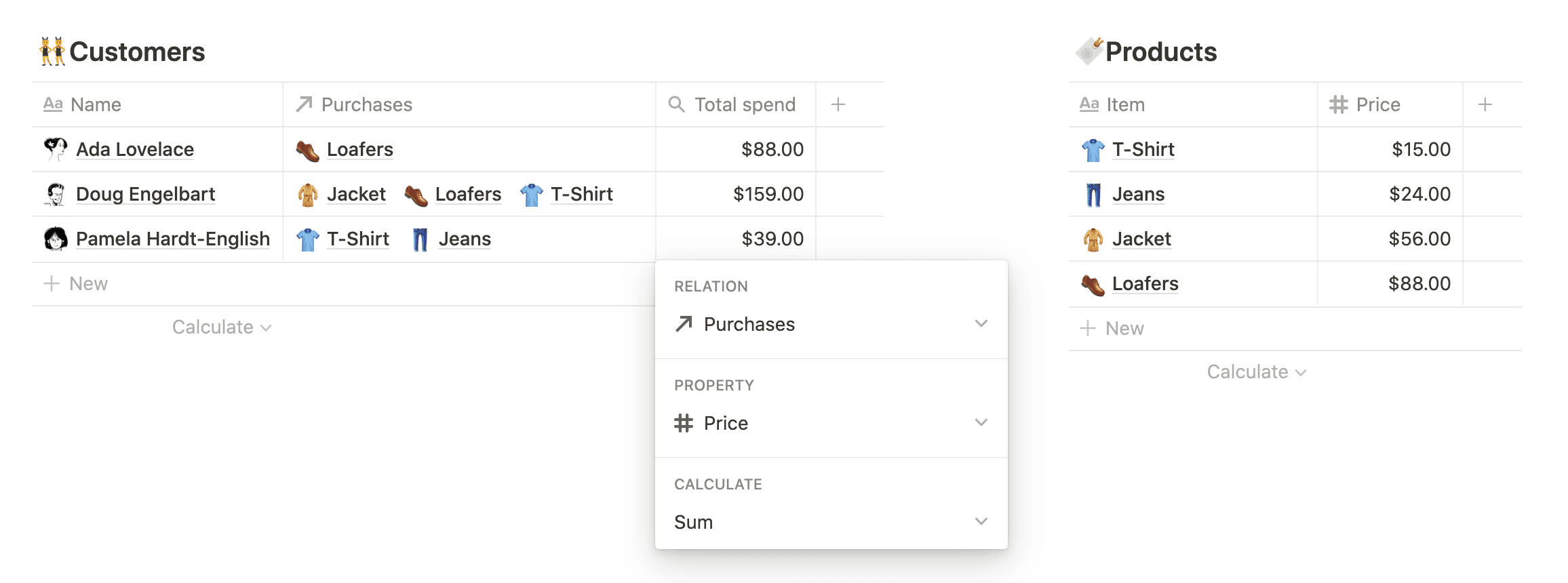
For each customer, the rollup looks at all products purchased, retrieves each product's price, and adds everything up.
Rollups aren't limited to numerical properties: you can summarize related pages as well. Here we configure a rollup on the 🔖 Products database to keep track of how many times each product has been sold.
Related database: 👥 Customers
Property: Purchases (relation)
Operation:
Count all
Internally, we store relations in a normalized form. This means that for a given product page, the related customers are stored as an array of page UUIDs, which serve as foreign keys into the 👥 Customers database.
Obviously we can't render these UUIDs directly to the user, so whenever we load a relation we need to look up each related page to retrieve its human-readable properties. This means that loading a single relation property can trigger many lookups: one for each related page in the other database!
Rollups add another layer of complexity. Since a rollup aggregates a property from all related pages, computing a rollup starts by loading the relation property as described above. Then, depending on the operation, we have to extract the relevant property from each related page, and aggregate the page properties. Simple operations like Count all are reasonably straightforward, but operations like Sum or Average require tracking intermediate state.
So what's the practical implication of all of this? The more relations and rollups are included on a page, the more lookups the API needs to perform and marshal, and the longer the response time will be. For enterprise-scale usage, unbounded latency would be a huge problem.
Paginating relations
The standard solution to computing arbitrary-sized data is to paginate: instead of loading and returning all results at once, we produce one fixed-size batch at a time, providing the client with a handle to request the next batch of results.
Pagination assumes that your results can be ordered. There are two main ways to allow clients to navigate this order:
Offset-based: Easy for developers to reason about, but can get out of sync if the underlying data is being updated in real time.
Cursor-based: Cursors can be references to server-side scroll states, or they can encode query parameters directly using Base 64 or a similar encoding.
Because users might be updating relations in real-time, we chose to implement cursor-based pagination for loading relation properties. This allows us to return a bounded number of pages from the relation property, and clients can perform additional requests until all pages have been returned.
Paginating numeric rollups
We can reuse this pagination logic for rollups, because loading a rollup requires loading the underlying relation. But there's a catch: just like spreadsheet formulas, rollups are computed live based on the related pages — and since we're loading the related pages incrementally, we may not have all of the data we need to compute the final rollup value!
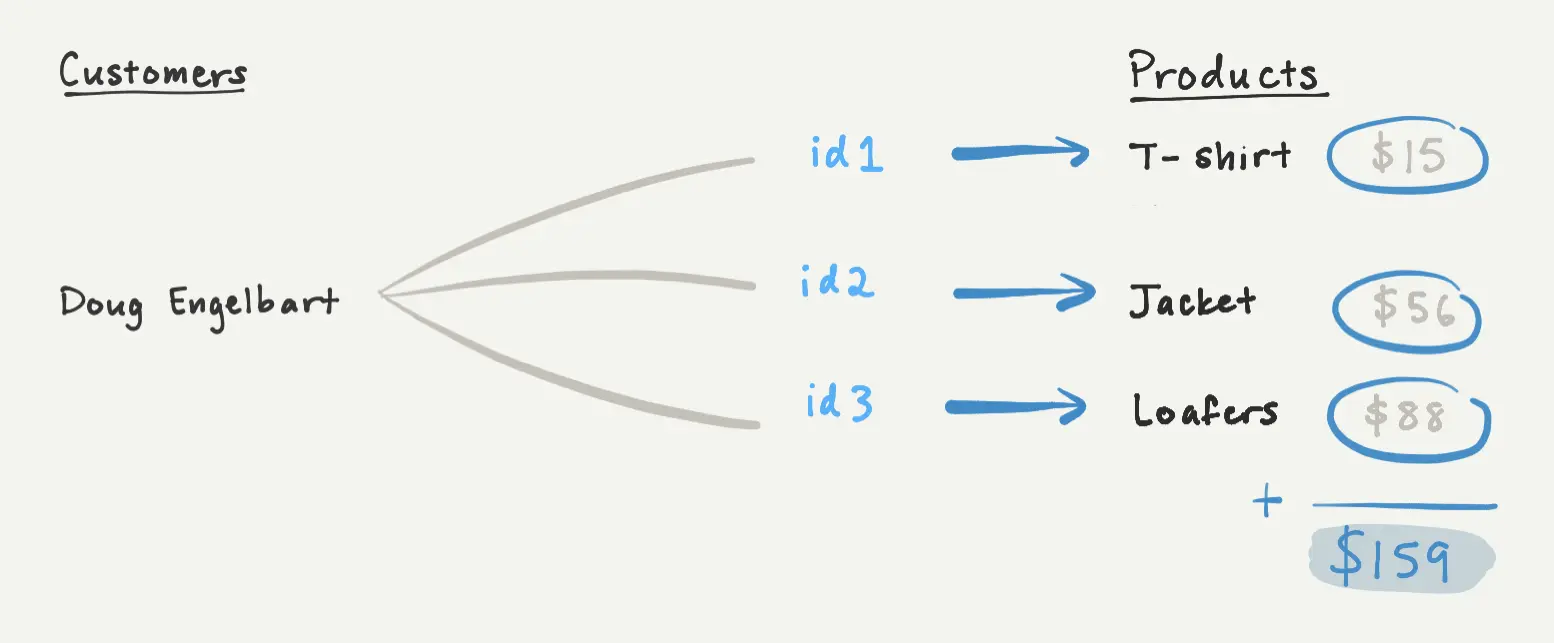
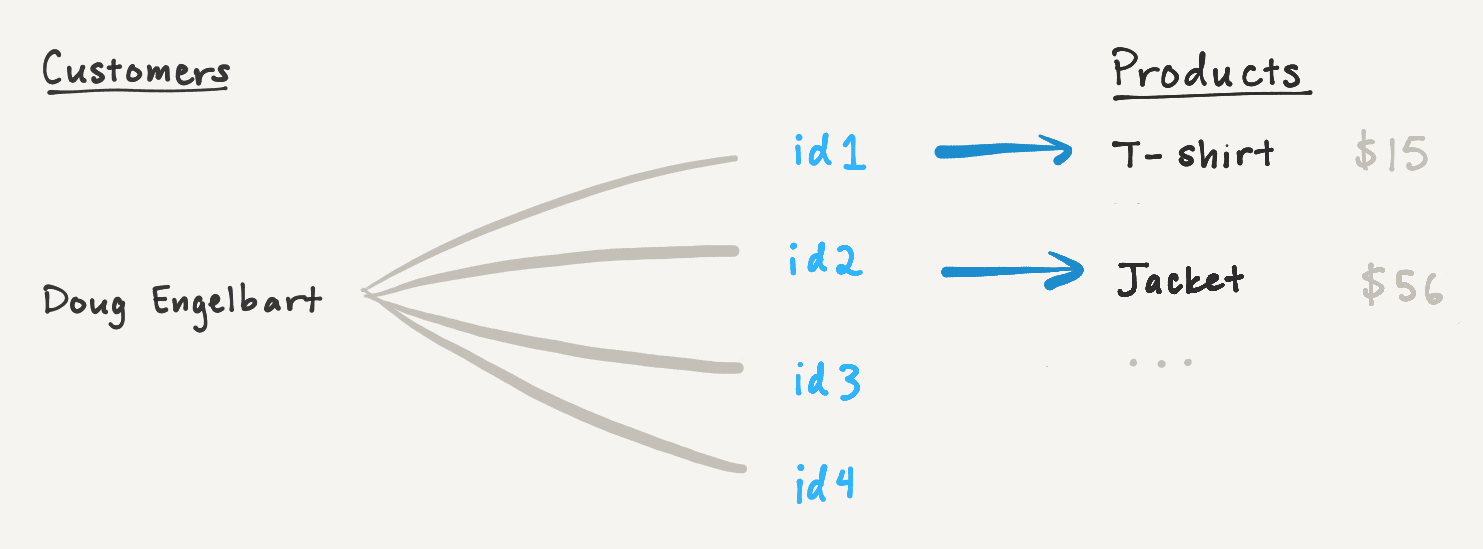
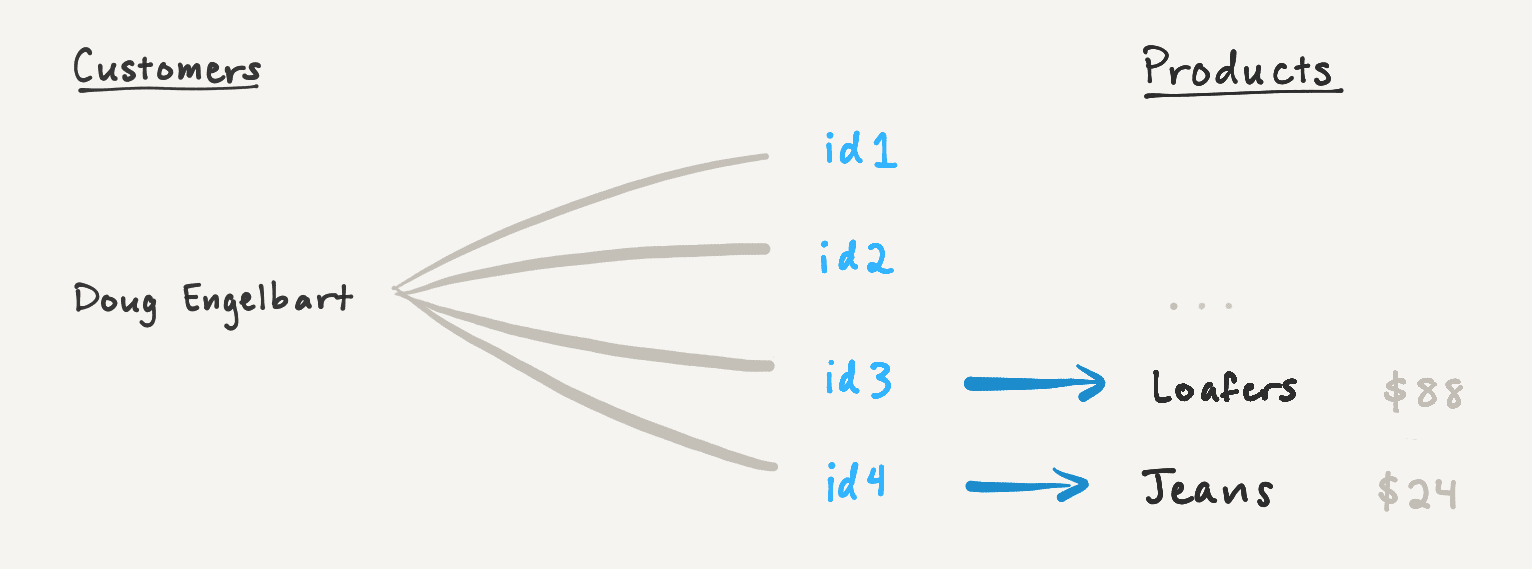
To illustrate, let's revisit the "Total Spend" rollup, which sums up the cost of all of Doug Engelbart's clothing purchases. If we load the "Purchases" relation in batches of two, the first response will only include the total cost of the pages loaded so far, which does not reflect Doug's total spend.
However, we can compute the partial result for the first two pages, and hash that result into the cursor as an accumulator. When the client makes another request with the cursor, we can update the accumulator based on the newly-loaded pages. By the time all pages have been loaded, the accumulator will reflect the final rollup value.
To paginate a sum rollup, we compute the partial sum for each batch of related pages. Each response includes a cursor encoding the next page and the partial sum of all pages loaded to date. Subsequent fetches can incorporate this partial sum, until all pages have loaded and the sum reflects the entire relation.
Encoding the result into the cursor works for many kinds of rollups, including Sum, Count, and Max. For Average, we also need to keep track of the number of pages loaded, in order to correctly weight the partial average. More generally, our approach works for any rollup with the following properties:
Embarrassingly parallel: We can divide the problem into independent subproblems, and combine partial results to eventually produce the global result. This requirement rules out rollups like
Median, which can't be subdivided unless all of the pages are globally ordered — which would require loading all of the pages to begin with.Sub-linear space representation: We need the accumulator(s) to grow slowly in order to encode them into the cursor without compromising ergonomics. For example,
SumandAverageare constant-space in JavaScript, where all numbers take up 64 bits regardless of size. This requirement rules out rollups likeShow unique values, which is parallel-izable (just compute the unique values across each subset) but requires a linearly-increasing amount of space (to encode all unique values seen thus far). Such a Base64-encoded cursor would quickly grow unwieldy.
For the few types of rollups that we cannot MapReduce, we simply return the underlying relation values for the client to compute directly.

Rollups over relation properties are even more complex than numeric rollups. This is because each related page must in turn fetch all of its related pages — requiring two dimensions of pagination! We use a two-dimensional cursor API for these cases.
Building for our users
With so much demand for the API, it would've been easy to let our commitment to quality slip in favor of delivering something quickly. But we wanted the API to live up to the promise of Notion itself: a powerful, flexible tool that you can mold to solve your problems. Sometimes that goal requires taking the hard way out: by introducing a custom JSON page representation, implementing versioning before the beta launch, or designing a new pagination scheme to handle tricky data dependencies.
Hard work feels all the more fruitful, though, when users build incredible things with the tools we've created. If you'd like to try out the API beta, head to our developer site to get started. And if you find yourself wishing for a particular bit of functionality, head to our careers page to get started on that part, too.
1. Most Markdown implementations support embedded HTML as well, which provides an "escape hatch" for more complex formatting. Unfortunately, supporting HTML-in-Markdown invites all the complexity of JSON — plus now you have to deal with parsing angle brackets. We didn't seriously consider this approach as a result.
2. We also considered using different formats for reading and writing content, such as Markdown for reading and JSON for writing. While this approach could have worked well for certain use-cases, developers wouldn't have been able to easily read a page, make edits, and send those edits back.